Using the dataset
Reading CSV file
Reading file from eclipse_mls_full.csv.
project.csv <- read.csv(file.in, header=T)We add a column for the Company, which we extract from the email address (i.e. the domain name):
project.csv$Company <- substr(x = project.csv$sender_addr, 18, 33)Number of columns in this dataset:
ncol(project.csv)## [1] 7Number of entries in this dataset:
nrow(project.csv)## [1] 676383Names of columns:
names(project.csv)## [1] "list" "messageid" "subject" "sent_at" "sender_name"
## [6] "sender_addr" "Company"Using time series (xts)
The dataset needs to be converted to a xts object. We can use the sent_at attribute as a time index.
require(xts)
project.xts <- xts(x = project.csv, order.by = parse_iso_8601(project.csv$sent_at))Plotting number of monthly posts
When considering the timeline of the dataset, it can be misleading when there several submissions on a short period of time, compared to sparse time ranges. We’ll use the apply.monthly function from xts to normalise the total number of monthly submissions.
project.monthly <- apply.monthly(x=project.xts$sent_at, FUN=nrow)
autoplot(project.monthly, geom='line') +
theme_minimal() + ylab("Number of posts") + xlab("Time") + ggtitle("Number of monthly posts")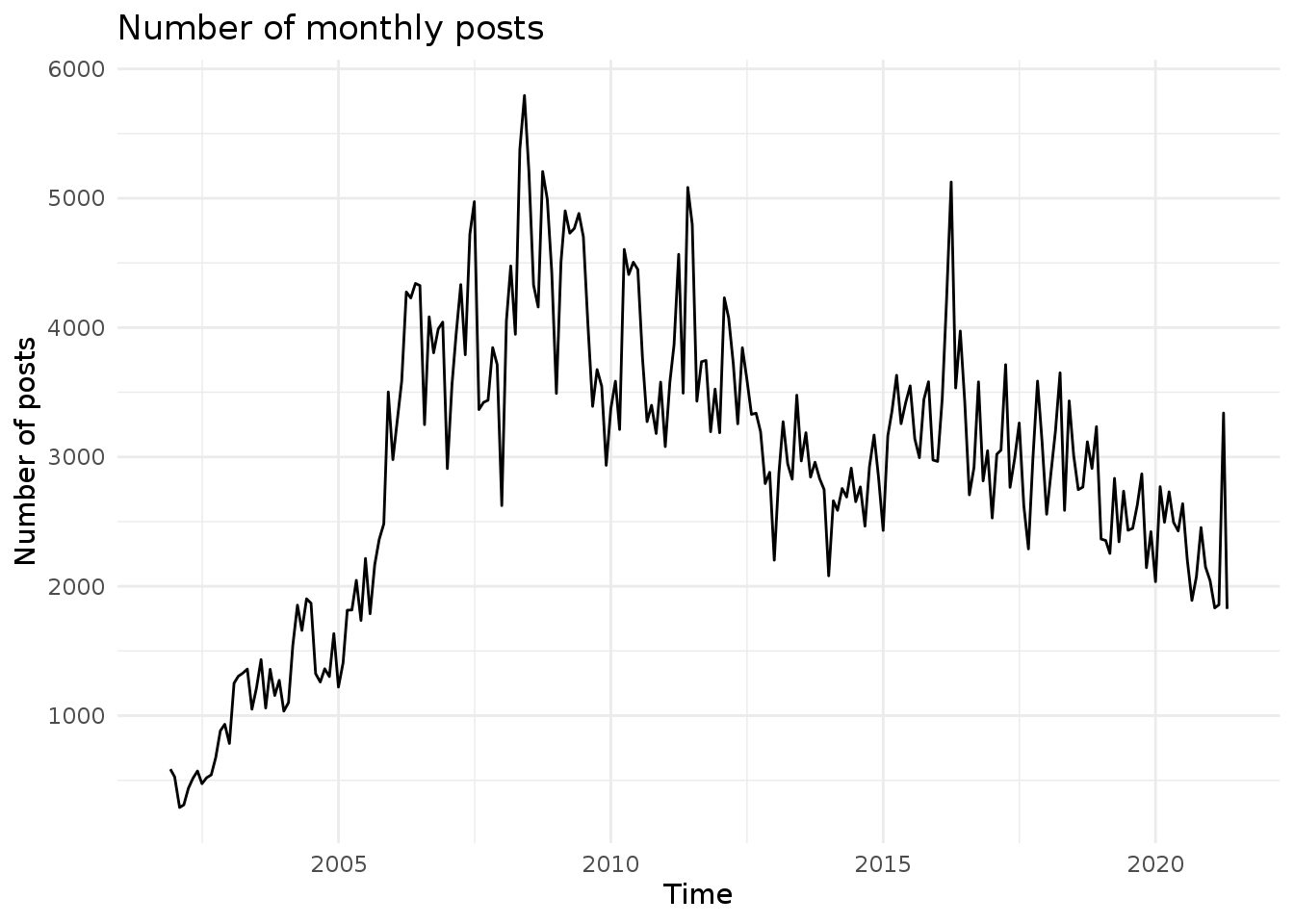
Plotting number of monthly reporters
One author can post several emails on the mailing list. Let’s plot the monthly number of distinct authors on the mailing list. For this we need to count the number of unique occurrences of the email address (attribute sender_attr).
count_unique <- function(x) { length(unique(x)) }
project.monthly <- apply.monthly(x=project.xts$sender_addr, FUN=count_unique)
autoplot(project.monthly, geom='line') +
theme_minimal() + ylab("Number of authors") + xlab("Time") + ggtitle("Number of monthly distinct authors")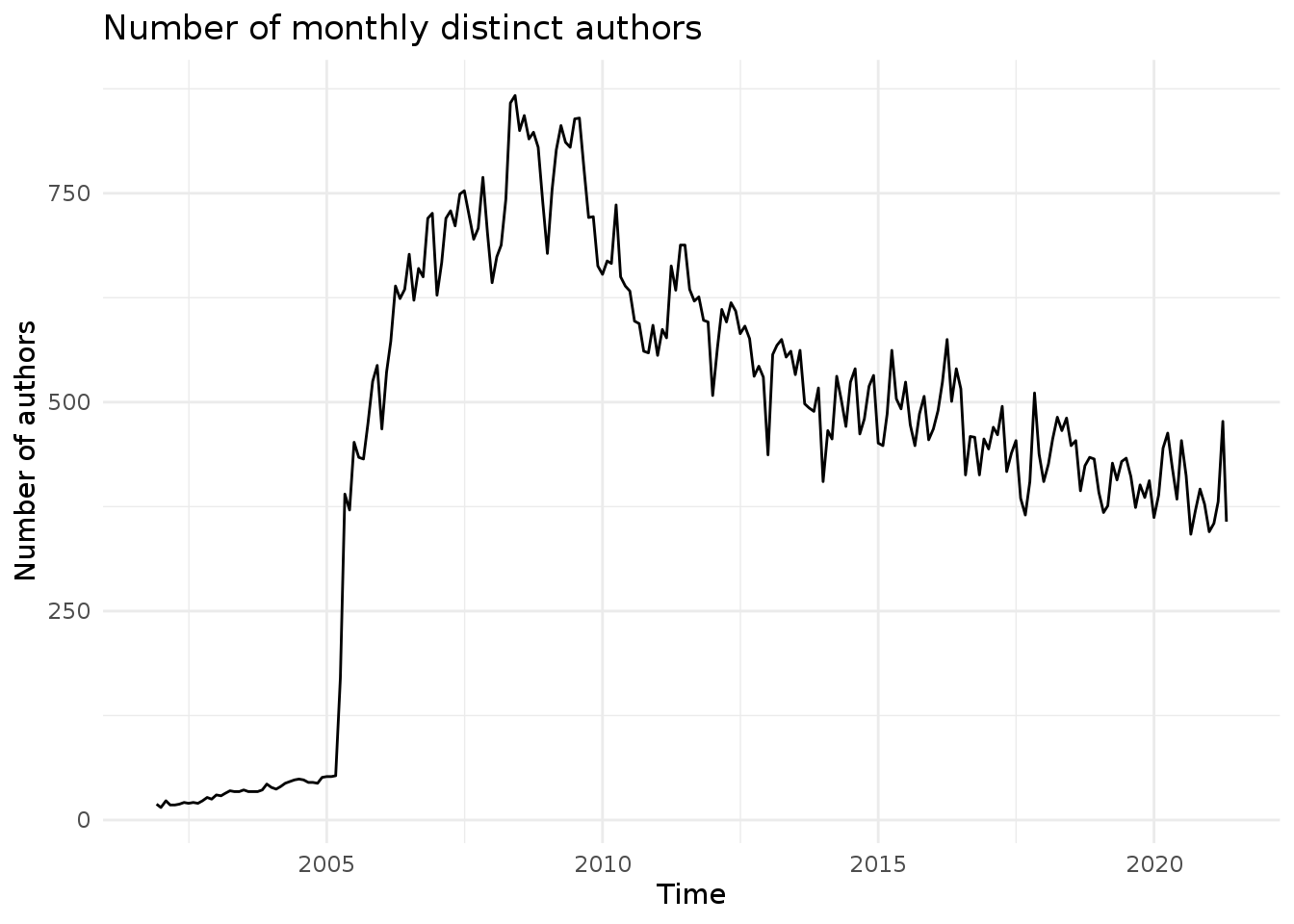
Posts by Company
We want to know what companies posted the most messages in mailing listsacross years. To that end we select the 20 companies that have the larger number of posts and plot the number of messages by company year after year.
comps_list <- head( sort( x = table(project.csv$Company), decreasing = T ), n=20 )
df <- data.frame(Company=character(),
Year=character(),
Posts=integer(),
stringsAsFactors=FALSE)
for (i in seq_along(1:20)) {
project.comp.xts <- project.xts[project.xts$Company == names(comps_list)[[i]],]
project.comp.yearly <- apply.yearly(x=project.comp.xts$Company, FUN=nrow)
for (j in seq_along(1:nrow(project.comp.yearly))) {
year <- format(index(project.comp.yearly)[[j]],"%Y")
comp <- as.data.frame(t(c(names(comps_list)[[i]], year, as.integer(project.comp.yearly[[j]]))))
names(comp) <- c("Company", "Year", "Posts")
df <- rbind(df, comp)
}
}
df$Company <- as.character(df$Company)
df <- df[order(df$Company),]
p <- ggplot(data=df, aes(x=Year, y = Posts, fill = Company)) + geom_bar(stat="identity") +
theme_minimal() + ylab("Number of posts") + xlab('Years') +
ggtitle("Top 20 Companies involved in Eclipse mailing lists across years") +
theme( axis.text.x = element_text(angle=60, size = 7, hjust = 1))
g <- ggplotly(p)
g#api_create(g, filename = "r-eclipse_mls_companies")